Insights 16: Claude Code: A Playbook for the Trillion-Dollar Opportunity
By Vu Ha - Technical Director

Foundation Capital's "Context Graphs" thesis names a trillion-dollar prize and makes a compelling case for where value will concentrate. This post offers a builder's blueprint for how to capture it, drawn from an unlikely source.
The Builder's Question
Foundation Capital argues that the next trillion-dollar enterprise platform will be built by whoever captures and serves decision context: not just outcomes stored in systems of record, but the full trace of inputs considered, policies applied, exceptions granted, and precedents that should inform future decisions. The core claim is that today's AI systems can retrieve information but cannot reliably answer "why was this decision made?" with enough structure and provenance for agents to act consistently or for humans to audit them. The essay frames this as a direct analogy to the last enterprise wave: the previous winners built systems of record (Salesforce, Workday, etc.), and the next winners will build systems of decision context.
The thesis is persuasive as a map of where value will concentrate, but it is deliberately silent on the question that matters most to builders: what does the agentic product actually look like? Foundation Capital and its interlocutors describe the destination without specifying the vehicle. These are product and UX problems as much as infrastructure problems, and the investor framing naturally abstracts them away.
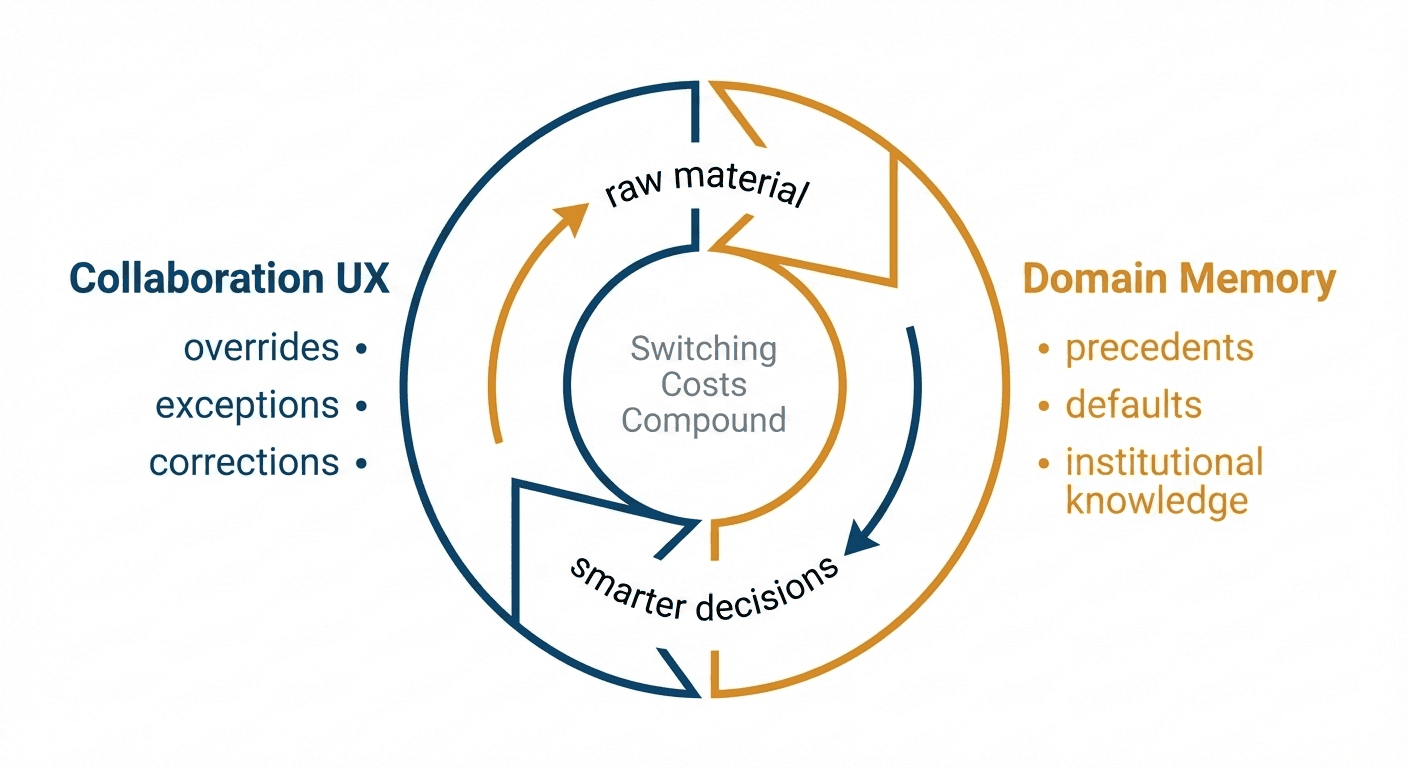
This post argues that the answer has two parts, and that the parts are not independent. The first is domain-specific memory: a layer that accumulates institutional knowledge from real execution, not just generic preferences or conversation history. The second is a collaboration UX where the surface that teams work on is also the mechanism that captures decision context. Each part is valuable alone. Together they form a flywheel: the collaboration surface produces the raw material that memory needs, memory makes the collaboration surface smarter, and each turn raises switching costs. The flywheel is the product.
The first credible sketch of how to build it arrived not from the context graph discourse but from a tool that was never designed to be a context platform at all.
Claude Code as Proof of Architecture
Around the same time Foundation Capital published its thesis, Claude Code was experiencing its own breakout moment. Andrej Karpathy called it an inflection point in his work as an engineer. The sentiment was widely shared: Claude Code turned the agent from a clever copilot into a participant in execution. It reads your codebase, proposes changes, runs tests, commits code, and remembers what you told it about how your team works.
Then users dragged it outside its intended domain, using it to organize research, manage projects, and automate workflows that had nothing to do with writing code. The tool's power turned out to be less about code and more about context: the ability to read, reason over, and act on a local environment. Anthropic's response made the point explicit. They built Cowork in roughly ten days, with 100% of the code written by Claude Code itself, repackaging the same agentic capabilities for general desktop work. A few months ealier they renamed the Claude Code SDK to the Claude Agent SDK, dropping "Code" from the name entirely. What had been built as developer tooling was revealing itself as a general-purpose context engine that happened to ship first in a terminal.
Claude Code is not a vertical product. But that is precisely what makes it useful as a blueprint. Three primitives do the structural work, and each generalizes well beyond code.
Skills are encoded workflows: the "how we do things here" that lives in someone's head until they leave. In Claude Code, a skill is a markdown file that packages instructions, templates, and scripts into a reusable command. /deploy runs your deployment checklist. /code-review enforces your team's standards. In commercial lending, skills become underwriting SOPs made executable: /credit-analysis pulls the borrower's financials, flags ratios outside policy, and prepares the summary for committee.
Subagents are specialized workers with constrained tools: the org chart made computational. In Claude Code, a subagent runs in its own context with its own system prompt, an "Explore" agent that can read but not write, a "code reviewer" that only sees diffs. In commercial lending, a credit subagent runs ratio calculations but cannot approve a loan; a compliance subagent checks the file against regulatory requirements and blocks the workflow if something is missing. They run in parallel when independent, sequence when dependencies exist, and return summaries rather than raw logs.
Tasks are the orchestration layer: persistent, shareable work items that separate what needs doing from how (skills) and who (subagents). In Claude Code, tasks break a project into trackable steps. In lending, each loan application becomes a task moving through intake, credit review, underwriting, approval, and closing, with the agent invoking the right skills and delegating to the right subagents at each stage.
Run a loan application through this stack and you do not just get an underwriting decision; you get the full trace of inputs considered, policies applied, exceptions flagged, and judgments made. The architecture does not require a separate context-capture project because the context is a natural byproduct of execution.
But in Claude Code today, skills, subagents, and tasks are all manually created and manually maintained. There is no mechanism for the system to learn from its own runs or accumulate the institutional knowledge that would make each cycle better than the last. That gap is where the real opportunity begins.
The Flywheel: Memory Feeds UX, UX Feeds Memory
Closing that gap requires something the models themselves cannot yet provide: the ability to learn continuously. LLMs ship frozen. The system that ran your workflow yesterday has no memory of what it learned, no way to improve from its own performance. This is the continual learning problem I flagged in Insight #13 two years ago; the problem has not gone away, but the workaround is now clear. If learning cannot live inside the model, it has to live somewhere else.
Claude Code has a basic version of an external memory layer: markdown files like CLAUDE.md where teams codify conventions by hand. That works for standards and preferences. It does not work for the institutional knowledge that only emerges from execution, the kind that should compound automatically but instead depends on someone remembering to update a file. And this is a structural constraint, not a maturity gap. Claude Code serves every kind of software project, so its memory layer must stay a least-common-denominator scaffold. Going deep on any single domain would make it irrelevant to the rest.
For founders building in a specific vertical, that constraint is the opportunity. The product can encode the domain's ontology, capture its exception patterns, and build memory structures purpose-fit for how decisions actually get made. Compounding kicks in fast. Every correction persists: "Flag any borrower with debt-service coverage below 1.25 for senior review." "For construction loans over $5M, require Phase II environmental before committee." These corrections do not vanish into a chat thread or a forgotten email. They become the default behavior the system repeats on every subsequent file.
But memory alone is only half the flywheel. Architecture without the right interface is infrastructure, not product. The frontend determines whether context actually gets captured, because that is where human decisions, corrections, and exceptions are expressed. Get it wrong and you have a powerful engine with no fuel.
Claude Code proved that the depth is buildable, but the interface is a terminal for one developer. Slack shows the other extreme: multi-player but shallow; you summon an AI to summarize a thread, and then it vanishes with no memory and no ongoing role. Neither has both. Enterprise work demands both, because decisions cross roles, require sign-offs, and involve specialists who each see a different slice of the problem. That combination does not exist yet.
The most expensive context loss in any organization is not within a role but between roles. In commercial lending, a single deal can pass through five or six specialists before closing, and at every handoff the institutional context thins out. The loan officer knows why the borrower's coverage ratio dipped last quarter; the underwriter who picks up the file does not. A senior underwriter overrides a threshold for reasons the committee never sees. Each transition forces someone to re-explain, re-justify, or re-discover what was already known.
Consider what this might look like in practice. The workspace is organized around the deal, not around a conversation between one person and one agent. Everyone on the deal sees the same shared context: history, decisions, and open questions in one place. When the file moves from intake to credit review, the underwriter does not start from a forwarded email and a PDF; she enters a conversation where the agent has already surfaced the relevant financials. When the senior underwriter overrides a threshold, she states the rationale and the agent captures it as precedent. When committee adds a condition, the reasoning is attached to the condition itself, not lost in meeting notes. Each handoff preserves institutional context instead of shedding it.
The UX details are speculative and would need real design work to get right, but the structural point holds: the collaboration surface and the context-capture mechanism should be the same thing. The agent that sits inside this workflow is not a collaboration feature. It is the continuity layer, and it is the core product.
This is where the two halves become a flywheel. The overrides, exceptions, and committee conditions captured in the shared workspace do not just preserve context for the current deal; they become precedents the memory layer serves back on the next one. The next deal runs faster, produces better traces, and feeds richer precedents back into memory. Each turn raises the switching cost. The closest analogy is what Figma did to Adobe. Figma did not win by adding features to a single-player design tool; it rebuilt the entire surface around how teams actually work, and in doing so created a flywheel Adobe could not replicate without starting over. The same opening exists now for AI-native workflows.
Why This Accrues to Verticals, Not Platforms
The question for founders is what kind of company to build on top of this architecture. Labs will keep improving the base model and shipping more general-purpose memory, more integrations, more agentic features. If the product is a thin wrapper, it will be competed away as soon as the next model release makes the wrapper unnecessary. If the product is horizontal infrastructure, the hard question is where value accrues once the stack stabilizes and incumbents embed the basics.
Big labs will ship native memory, but it will be generic: preferences, conversation history, lightweight fact extraction. They will not ship the company-specific exceptions or the tribal knowledge that never got documented, because those only emerge from living inside real execution. Memory startups like Mem0, Letta, and Zep are doing important work and can accelerate the basics, but a vertical company still has to go much deeper than a plug-in memory layer.
The founders with the best odds are the ones who go uncomfortably deep: encoded skills that match the job's actual SOPs, domain-specific memory that turns exceptions into precedent, and a collaboration UX that captures decision context as a byproduct of how teams already work together. The depth is the moat. It is not something a platform can replicate from the outside, because the knowledge only accumulates from inside the workflow.
The Window Is Open
The reason this moment feels different is not hype. It is that the two blockers, a workable approach to memory (Insight #13, January 2024) and reliable agentic execution (Insight #15, January 2025), are finally starting to move at the same time, and that rarely happens in platform shifts. Claude Code is the tell: not a vertical product, but the most legible proof that the architecture works and that users will trust it with real work.
The founders who will capture the most value are building where the flywheel turns fastest: workflows with high exception volume, multiple specialist handoffs, and expensive context loss between roles. That is where domain memory compounds quickest, where the collaboration UX produces the richest signal, and where switching costs build before incumbents can respond. The moat is everything the system learns after you ship it.
Appendix
A Note on Tools and Frameworks
This essay uses Claude Code as the reference architecture because it makes the patterns legible, not because it is the only way to build. Builders are shipping agentic systems with LangGraph, CrewAI, the Claude Agent SDK, and other frameworks, and evaluating them with tools like Galileo and Braintrust. The framework layer is important but it is not where defensibility lives. The patterns this essay describes, encoded skills, constrained subagents, persistent tasks, can be implemented in any of these. What cannot be replicated across frameworks is the domain memory and collaboration UX you build on top of them. Pick the framework that fits your team and your constraints. Invest your differentiation budget in the layers above it.
Where to Look
Foundation Capital's signal is simple: go where the headcount is. When a company has fifty people manually routing tickets, triaging requests, reconciling data, or pushing approvals through a maze, that is proof the decision logic is too complex for traditional software, and there is real economic surface area for agents to absorb judgment, not just automate keystrokes. The best hunting ground is workflows where exceptions are the norm: deal desks, underwriting, compliance reviews, claims adjudication, escalation management, renewals, collections. The second is the "glue" functions: RevOps, DevOps, Security Ops, and similar roles that exist because no system of record owns the cross-functional workflow. These are natural entry points for an agentic layer that holds context through handoffs instead of letting it die. When pricing comes up, anchor to headcount replaced and contractor spend displaced, not to seats. Seat-based pricing invites immediate comparison to commodity SaaS.
How to Handle Integration Walls
Deep integrations are not an implementation detail; they are part of the stack. Claude Code makes this legible with MCP, a standardized way for agents to connect to external systems without rebuilding integrations from scratch. The architecture is directionally right, but the ecosystem reality is getting harsher: more incumbents are treating APIs as strategic choke points, throttling access, changing terms, or using policy enforcement to block competitors. Walls appear around assets that matter. If the incumbent is defensive, the workflow is usually valuable. Build for the user's workflow, not for the incumbent's preferred integration surface. Use MCP when you can; design your product to route around closed doors when you must, including computer-use approaches where the agent operates through the UI like a human. These walls do not hold forever. In 1968, AT&T prohibited third-party devices from connecting to its phone network; the Carterfone decision forced openness, and what followed were modems, fax machines, answering machines, and eventually the internet. The value created after forced openness dwarfed what the incumbent was protecting. Today's API walls will follow the same pattern, and the winners are the teams that keep shipping value while the platform politics shift beneath them.
The Context Graphs Discourse
Foundation Capital's thesis triggered broad convergence around a shared intuition: context, not model cleverness, is the bottleneck for agentic systems. Aaron Levie (Box) broadened it into an "age of context" argument; Dharmesh Shah (HubSpot) emphasized converting tribal knowledge into queryable precedent; Nick Mehta (Gainsight) described a sufficiently rich context graph as a world model for "organizational physics." Several participants mapped the thesis to concrete beachheads in marketing, GTM, and collaboration workflows. The consensus was wide. The disagreements were more interesting.
The most productive fault line was where context graphs should originate. Arvind Jain (Glean) argued the unlock is enterprise-wide observability: capture and model the "how" of work, because much of the true "why" will always live in human judgment and tacit tradeoffs. Ashu Garg (Foundation Capital) pushed back that observability sits in the read path, which means decision context has often already been flattened by the time it becomes observable; an orchestration layer in the execution flow can record decision traces at commit time and produce a more authoritative substrate. This split, read-path versus write-path, implies different product wedges, different integration strategies, and different trust models for agentic systems. The main essay's argument sides with the write path: the most valuable context is captured by the system that is present when the decision is made, not the one reconstructing it afterward.
Not everyone was persuaded. Satyen Sangani (Alation) warned that "context graphs" can become a distraction from building applications that create value and make context capture inevitable; the right near-term posture may be decision support with strong lineage, not fully autonomous decisioning. The sharpest structural counterargument came from Atlan, whose co-founder argued that value will not accrue to vertical agents in the execution path but to the integrator that builds a universal context layer, because most real decisions need context spanning many systems and vertical agents would produce fragmented traces that are hard to govern and reuse. This perspective should be read with an explicit caveat: it maps cleanly onto Atlan's own product positioning around integration, governance, and active metadata. The substantive question it raises is real nonetheless: whether a universal layer can capture high-fidelity decision traces from outside the workflow, or whether vertical agents embedded in execution will win by collecting better traces faster and closing tighter outcome loops.